バーチャルスクリーニングの指標のテスト
久しぶりの記事.久しぶりすぎたのでテンプレも変えた.
最近バーチャルスクリーニング(virtual screening)という話を勉強中である.
簡単に言うと,薬(でもなんでも)のモトになるligand(とか)を計算機で選別しましょう,というもの.
話すと長くなるので詳細は割愛するが,例えばprotein-ligand dockingなんかで有望そうな化合物(ligand)を選別したいのだ.この有望そうな化合物はよく「ヒット化合物」とか言われる.
選別する手法はものっすごくたくさんあるのでこれも割愛するが,どんな手法が良いのかの基準というものがないと手法の良し悪しが測れない.
手法の良し悪しは「early recognition problem」として評価することが多いようだ.early recognition problemとは,端的に言えば「上の方の順位にヒットがいたら優秀」というわけだ.
イメージはこんな感じ.
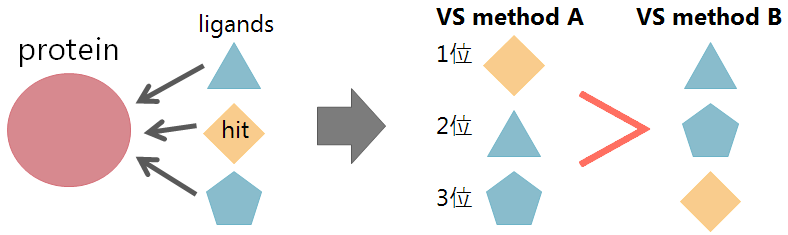
この例だとぱっと見で手法Aが優秀だとわかるが,実際はもっとごたごたしている.もっとたくさんの化合物を試すし,ヒットは複数ある場合も多い.
というわけなので,定量的に評価する指標が存在する.今日は2つ紹介する.ARPとRIEである.
ARP (Average Rank of Positives)
なんか大層な名前が付いているが,要はヒットの順位の平均である.
はヒットの数,
は(
個目の)ヒットの順位である.
定義から分かる話だが「小さい方が良い」値である.簡単に求められるし直感的だが,テストした化合物の数やヒットの数などでどのくらいの値が良いという話が変わってくるのであまり実用的ではない.
RIE (Robust Initial Enhancement)
こちらはもうちょっとマシな指標であるが式はごたごたしている.
はヒットの数,
は(
個目の)ヒットの順位なのはARPと同じ.
はテストした化合物の数,
は謎パラメータである.一応Enrichment Factorという別の指標の
の逆数と似たような意味,という意味合いのパラメータではあるが,今回は厳密な意味は割愛する.だいたい
とかが選ばれる.8.0だと「上位20%ぐらいに入ってて欲しいなぁ」という話になる(はず).
RIEは「大きいほど良い」値である.ランダムだと1になることが証明されている.
(というか元々は分母は分子の値をモンテカルロで1000回とかランダム計算してそのアンサンブル平均にしてね,という話だったのを,Truchon J-F and Bayly CI, J Chem Inf Model, 47:488-508, 2007 でちゃんと閉じた形で計算できるようになった,というわけ.)
さて,この2つの指標をテストするpythonプログラムをサクッと書いた.
#!/usr/bin/python import sys import math if len(sys.argv) != 3: print 'Usage: %s [N] [list of hits (ex: 2,3,5)]' % sys.argv[0] quit() N = int(sys.argv[1]) hits = sys.argv[2].split(",") n = len(hits) ri = 1 arp = 0.0 rie = 0.0 alpha = 8.0 # RIE paramater for i in range(1, N+1): if str(i) in hits: arp += ri rie += math.exp(-alpha*ri/float(N)) ri += 1 arp = arp / float(n) rie = rie / ((float(n)/float(N))*((1-math.exp(-alpha))/(math.exp(alpha/(float(N)))-1))) print "ARP =", arp print "RIE =", rie
最初の引数が,次の引数がカンマ区切りのヒットの順位である(スペースを入れると動かない).
$ python virscr.py 10 1,2,4,6 ARP = 3.25 RIE = 2.14608273845
のように使う.
例えば

の結果からAとBのどちらが良いかというのを見てみる.(見た瞬間にAの方が優秀だということが分かるが,値で確認してみよう.)
$ python virscr.py 4 1,3 ARP = 2.0 RIE = 1.76159415596
$ python virscr.py 4 2,3 ARP = 2.5 RIE = 0.265802228834
というわけで,ちゃんとAの方が「ARPは小さく」,「RIEは大きく」なっていることが分かる.